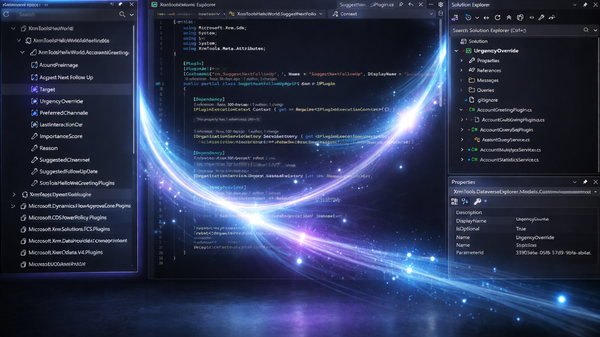
powerplatform Xrm Tools 1.5.9 – Introducing Dataverse Explorer Xrm Tools 1.5.9 introduces Dataverse Explorer, a new Visual Studio tool window that lets developers explore assemblies, plugins, steps, images, and Custom APIs directly from their Dataverse environment. Navigate metadata, inspect properties, and jump to code without leaving Visual Studio.
powerapps Smarter Power Platform Development with Xrm Tools 1.5.8 Xrm Tools 1.5.6 introduces built-in code analyzers and fixers for Power Platform plugin development. Common mistakes are now detected directly in Visual Studio, with one-click fixes where possible and AI-assisted guidance when needed.
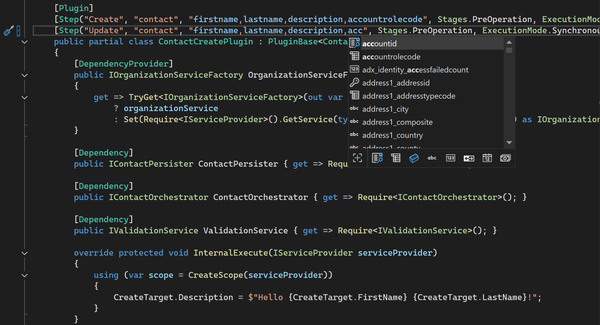
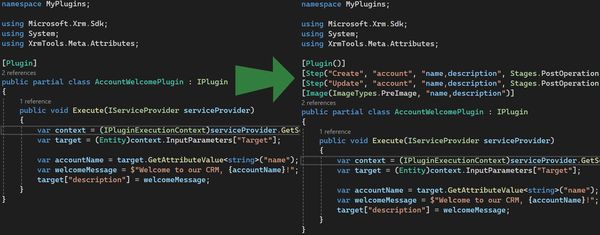
powerapps Xrm Tools now generates code-behind for plugins on any message Xrm Tools v1.5.7 brings message-aware code generation for Dataverse plugins. Your code-behind now adapts to any message—Create, Delete, Merge, or Custom APIs—generating the right input properties automatically. Less SDK plumbing, more real logic.
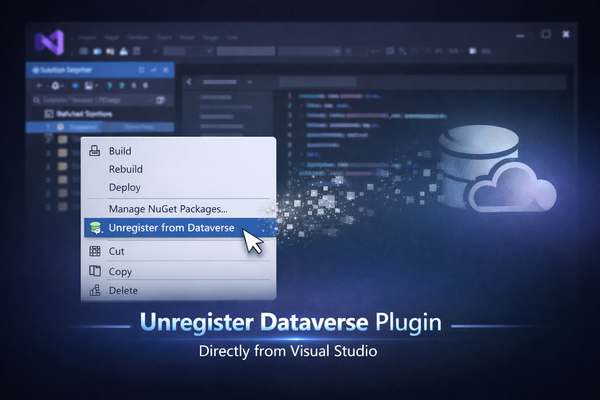
power apps Unregister Dataverse plugins without leaving Visual Studio Unregistering Dataverse plugins shouldn’t be painful. With Xrm Tools v1.5.6, you can now unregister an entire plugin assembly or package directly from Visual Studio with a single click. No extra tools, no leftovers, just a clean and reliable unregister.
powerplatform Convert Power Platform Plugin projects to SDK-style Modernize legacy Dataverse plug‑in projects by converting them to SDK‑style .csproj files. This format is required for packages, simplifies project files, improves package management, and the post shows how to migrate.
powerapps Xrm Tools 1.5.0 - FetchXML becomes a native language in Visual Studio Xrm Tools 1.5.0 brings native FetchXML support to Visual Studio — with IntelliSense, live query previews, and automatic C# code generation, all powered by your connected Power Platform environment.
power platform Xrm Tools 1.4.4+: Easier Updates, Less Hassle Xrm Tools 1.4.4+ makes keeping your projects up to date easier than ever. Visual Studio now notifies you when the XrmTools.Meta.Attributes NuGet package is out of date, and new utility methods simplify writing plugin code.
powerplatform Xrm Tools v1.4.3 – Small Release, Big Quality of Life Xrm Tools v1.4.3 is a polish release with quality-of-life improvements: cleaner code generation, entity inheritance, named DI dependencies, sharper IntelliSense, improved colorization, and key bug fixes for smoother plugin development.
power platform Xrm Tools v1.4 – Smarter Code Generation, One-Click Registrations, and Compile-Time Dependency Injection Xrm Tools v1.4 introduces compile-time, thread-safe dependency injection for Power Platform plugins and custom APIs, smarter one-click registrations, enriched metadata, and optimizations—helping developers focus on business logic while the tool handles the complexity.
Automatically Generate Plugin Registration Attributes with Xrm Tools v1.3.0 In previous posts like Xrm Tools for Visual Studio , I explained the benefits of having a first-class development experience when building plugins using Xrm Tools. Starting from scratch with Xrm Tools is a joy—code completion, IntelliSense, and rich refactorings help you every step of the way. But what
XRM Tools for Visual Studio — Official Release After weeks of hard work, countless improvements, I’m thrilled to announce the first official release (no longer in preview!) of the XRM Toolkit for Visual Studio — an extension that brings Power Platform development natively into Visual Studio. Whether you’re building plugins, custom APIs, or simply want a smarter,
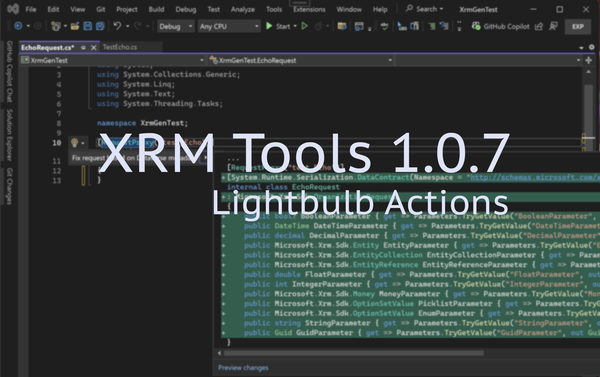
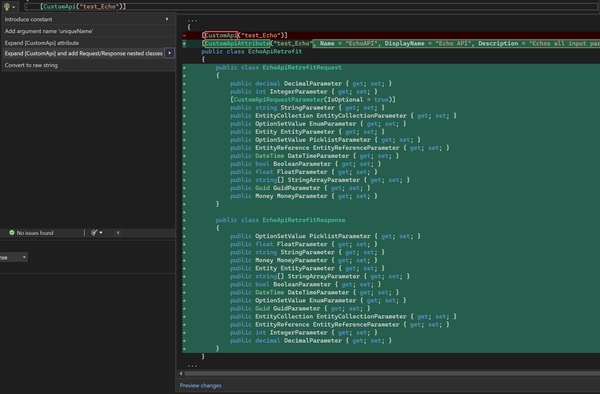
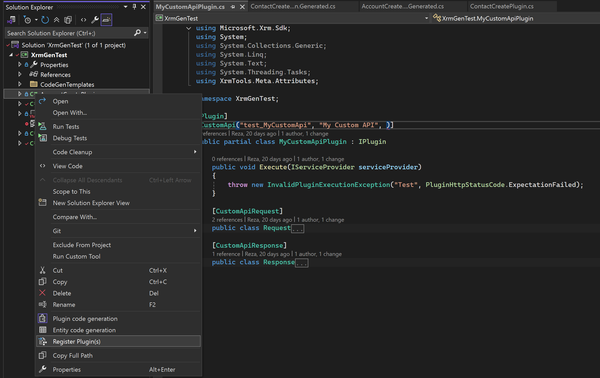
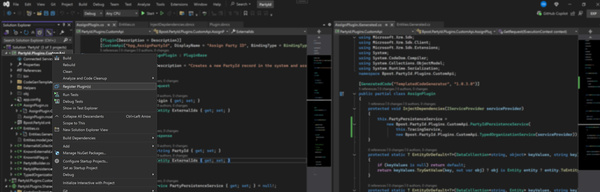
Xrm Tools v1.0.7 Released – Write client code to call Power Platform (Custom API, actions et all) with a click. Xrm Tools just got a major productivity boost in version 1.0.7 with a brand-new Roslyn-based code refactoring provider that makes calling Custom APIs, Custom Actions, and even standard Power Platform messages easier and more intuitive than ever before – all from within Visual Studio. It also helps
Xrm Tools v1.0.5 Released - Smarter Plugin Registration with Refactoring Actions I’m excited to announce the release of Xrm Tools v1.0.5, a powerful Visual Studio extension designed to accelerate plugin development for the Power Platform. This release introduces a new productivity feature: refactoring actions that automatically complete plugin registration attributes and boiler plate code—saving you time, reducing
Xrm Tools v1.0.4 – Smoother Power Platform Development Inside Visual Studio I’m excited to announce the release of Xrm Tools v1.0.4, a Visual Studio extension designed to simplify and accelerate plugin development for Microsoft Power Platform. With this version, I’ve focused on usability improvements, new features, and a much-requested addition: comprehensive documentation! Developers can now onboard
Xrm Tools for Visual Studio After nearly a year of dedicated work, I’m excited to introduce my Visual Studio extension built specifically for Power Platform developers. As someone who’s spent countless hours working with plugins and custom APIs, I’ve experienced firsthand the unique challenges that come with building solutions on top of
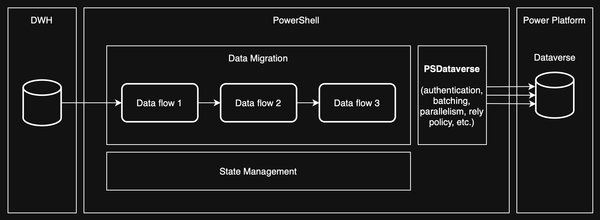
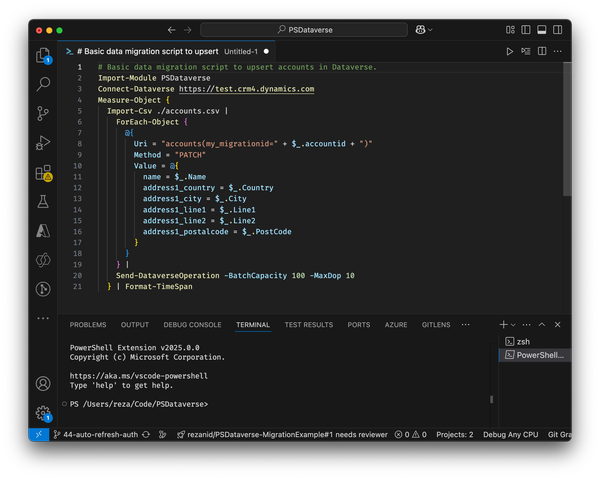
Data Migration as Code - Enhancing Observability and Reliability In my previous post, I introduced the concept of Data Migration as Code in Power Platform, exploring how automation and scripting can bring consistency, repeatability, and efficiency to the migration process. I discussed the challenges of traditional data migration approaches, the benefits of treating migration as code, and how tools
Power Platform Data Migration as Code I’m sure that wherever you are in your software engineering journey, you have already heard or done something-as-code. History The “as code” movement began gaining traction in the early 2010s, particularly with the rise of DevOps and cloud computing. The concept builds on software-defined everything (SDx)
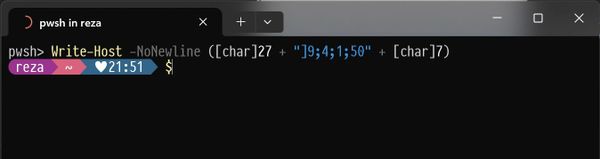
How to display progress wheel in Terminal Yes you read that title right. You can display a cool progress wheel in Terminal. You know Terminal, right? Right? Ok, then I just cut to the chase. The following PowerShell command will display a 50% completed wheel. Write-Host -NoNewLine ([char]27 + "9;4;1;50" [char]
Development How to check your public IP using PowerShell Theoretically you can't reliably lookup your public IP address inside your local machine. You might be behind a proxy, using a VPN and other situation that translate your public exposure. The best way to reliably lookup your public IP address is to ask an outside service to tell
Development Streamline Power Platform Plugin Troubleshooting with a Custom Postman Visualizer Use a custom visualizer in Postman for troubleshooting Power Platform plugins.
Development Automatically Authenticate in Postman with Pre-Request Scripts In the modern development landscape, testing and interacting with APIs is a critical task. Postman emerges as a powerful tool in this regard, offering extensive features for sending requests, testing, and documentation. However, when it comes to API authentication, especially with OAuth2.0, developers often face challenges. The manual process
Development Using Dataflows and Power Automate for continuous data integration Power Platform's Dataflows are a capable data integration tool that are often overlooked when it comes to transferring data out of Power Platform. They provide a wide range of connectors to extract and transform data from variety of sources. It is also possible to create custom connectors through
Development How to export large number of rows from Power Platform - The easy way So you need to export a large number of rows from Power Platform or more specifically Dataverse. You might need to extract data from more than one table, join, transform, map, cleanup as well. Usually after going through the requirements, one of the first things that comes to mind is
Development How to convert a list of records to table in Power Query - A better way When parsing JSON files in Power Query, there will most likely come a step that you'll need to convert a list of records to a table. Say you have a JSON document like the following. [{"name": "Reza", "age": "20", "
Development Exporting Global OptionSet Labels and Values from Power Platform using PSDataverse and PowerShell Microsoft Power Platform provides a rich set of capabilities for creating robust business solutions, among which is the option to use Global OptionSets. These are predefined sets of options that can be used across multiple entities. As developers and analysts, there are often requirements to extract this data for various